Introducing a network structure
So far, we have considered a population in which every agent is connected with every other agent. However, in real populations, individuals are generally only in contact with a small section of the total population. These contact structures depend heavily on the locations the individual frequents, and other agents who frequent this location, and can – in principle – depend on other attributes like their age, gender, and socio-economic class. In order to implement this heterogeneity, we will now need to implement an underlying network structure to our model, with individuals being associated with certain locations, and interacting with other individuals who are associated with those locations.
Consider the semi-realistic scenario where agents can move between different locations like “work” and “home”. We can build a network that accounts for the relationship between agents and locations over time.
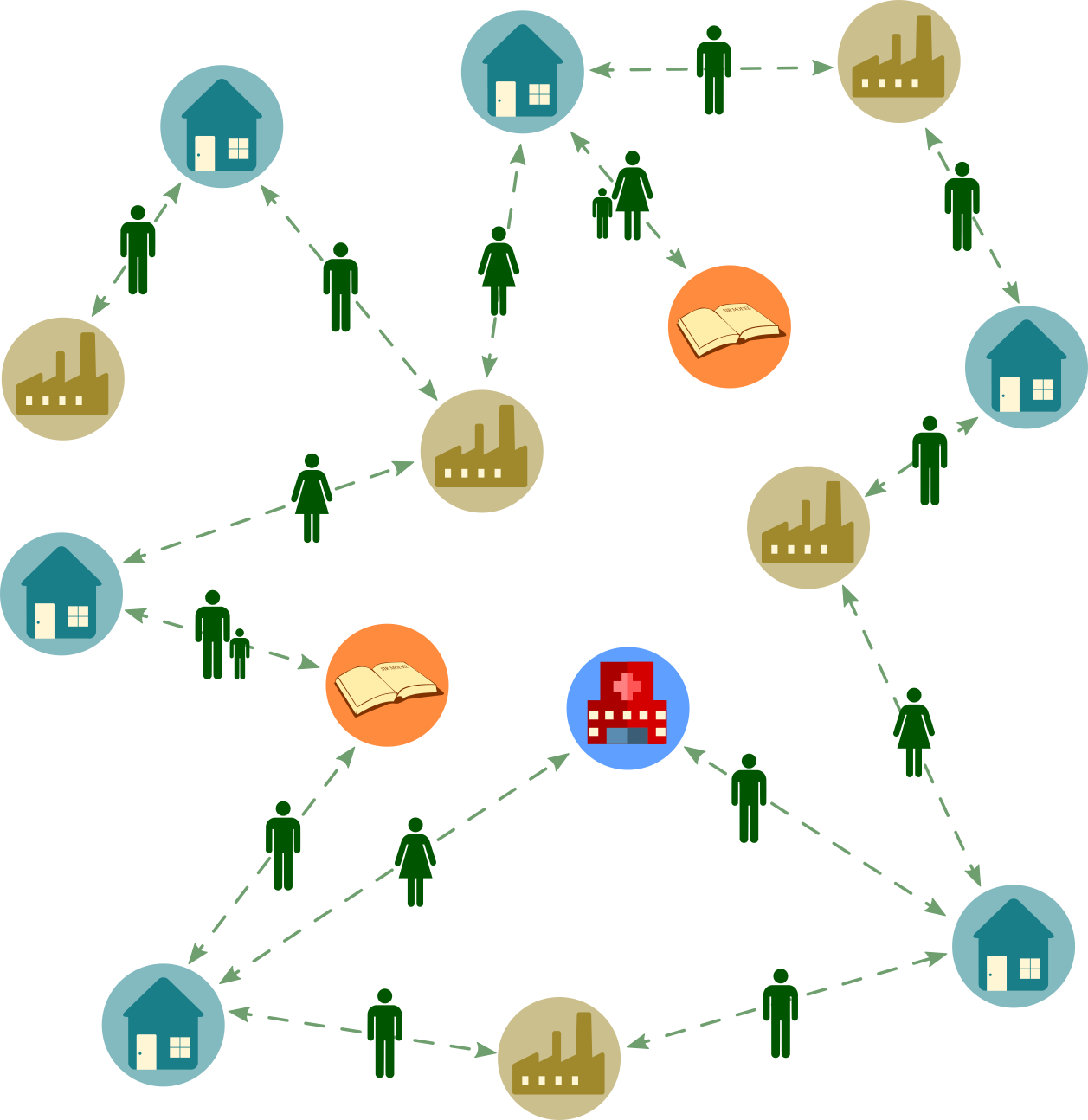
By adding this complexity, we can see that the number of individuals at any given location is not fixed. So we modify our algorithm such that we treat each location as a well-mixed case looping over the instantaneous population at the given location. The modified algorithm is shown in the box below.
Algorithm
Divide the total time into steps of \(\Delta t\), and at every time-step we loop over all agents.
If the agent is susceptible, we compute the number of infected individuals who could potentially infect them (”\(I\)”) in their current location. Then, with some probability
\[p_\text{SI} = \lambda_S\frac{I}{N}\Delta t,\]we transition them to the infected compartment.If the agent is already infected, we transition them to the recovered compartment with a probability
\[p_\text{IR} = \lambda_I\,\Delta t.\]If they have recovered, do nothing.
Repeat the entire process until there are no more infected individuals, or the total time has elapsed.