Miscellaneous
Assembling an Executable .jar file
A jar file is an executable java file that can be used to run your code. Instead of importing and building the whole project, it is more efficient to convert the source code into a jar and import it as a library. This way the environment will be clutter free and all the classes and functions can be easily imported.
In order to assemble the code into an executable jar that can be used as a library, open the project in IntelliJ and go to the sbt shell, and type assembly.
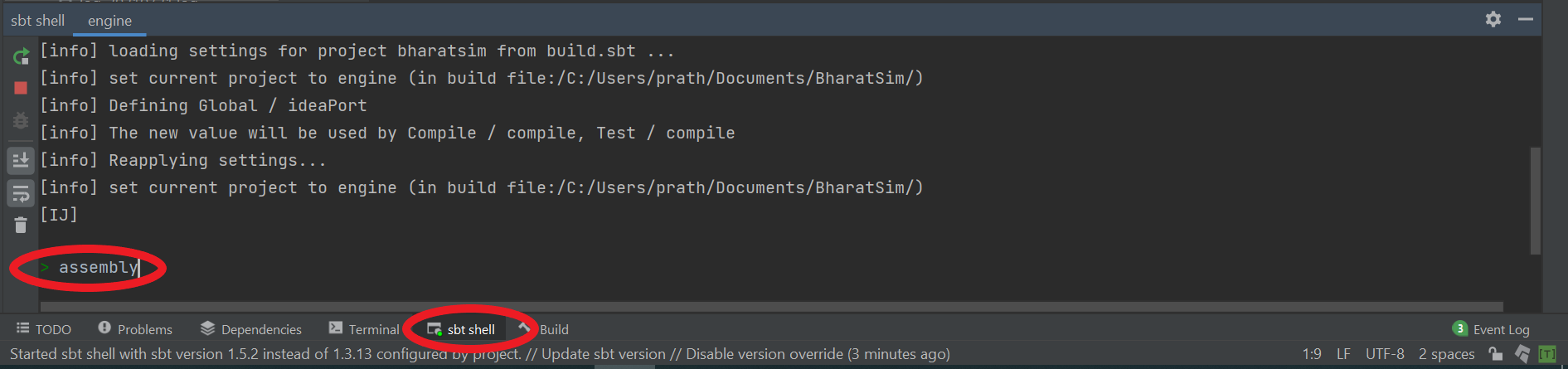
Alternatively, you could also navigate to the root folder of your project in a standard UNIX terminal and type sbt assembly. Once this command has successfully run, a new jar file will appear in the target/scala-2.##/ within the root folder of your project.
Importing a .jar file as a Library
As mentioned in the above section, importing the whole source code as a jar file is highly efficient and recommended, especially for a novice coder. In the root folder of the project, create a new folder called lib unless one already exists. Copy the jar file and paste it into the lib folder.
Go to file option in IntelliJ and click on the option “Project structure”.
Select “modules” on the left side panel, and select the “dependencies” option. A list of files should appear.
There should be a “+” option and select the Library followed by Java.
Select the required jar file in the lib folder. Click on
Applyand thenokbutton to import the jar file.
Error
If the package or a class from the library is not available, then make sure the jar file has been imported successfully. Once common source of error is not clicking on the Apply button before selecting ok as mentioned in Step 4.
Importing packages and classes can be done as before using the same syntax.
Using args in main method
While using the run command on the sbt shell, one can pass in some string arguments. These arguements can be called by the main function.
For example, one might want to change the name of the output file everytime they run the code. Instead of changing the output name manually each time, one can write a code like the one given below.
def main(args: Array[String]): Unit = {
outputName = args(0)
}
One could use the outputName and use it in the name of the csv file, for eg.
SimulationListenerRegistry.register(
new CsvOutputGenerator(outputName+".csv", new SEIROutputSpec(context))
)
To implement this, one must go to the sbt shell and type run "my_sir_model". If this were to be used on the code-block above, the output csv file will be named as my_sir_model.csv. However, if one runs the file without specifiying the arguement, it will show an error:
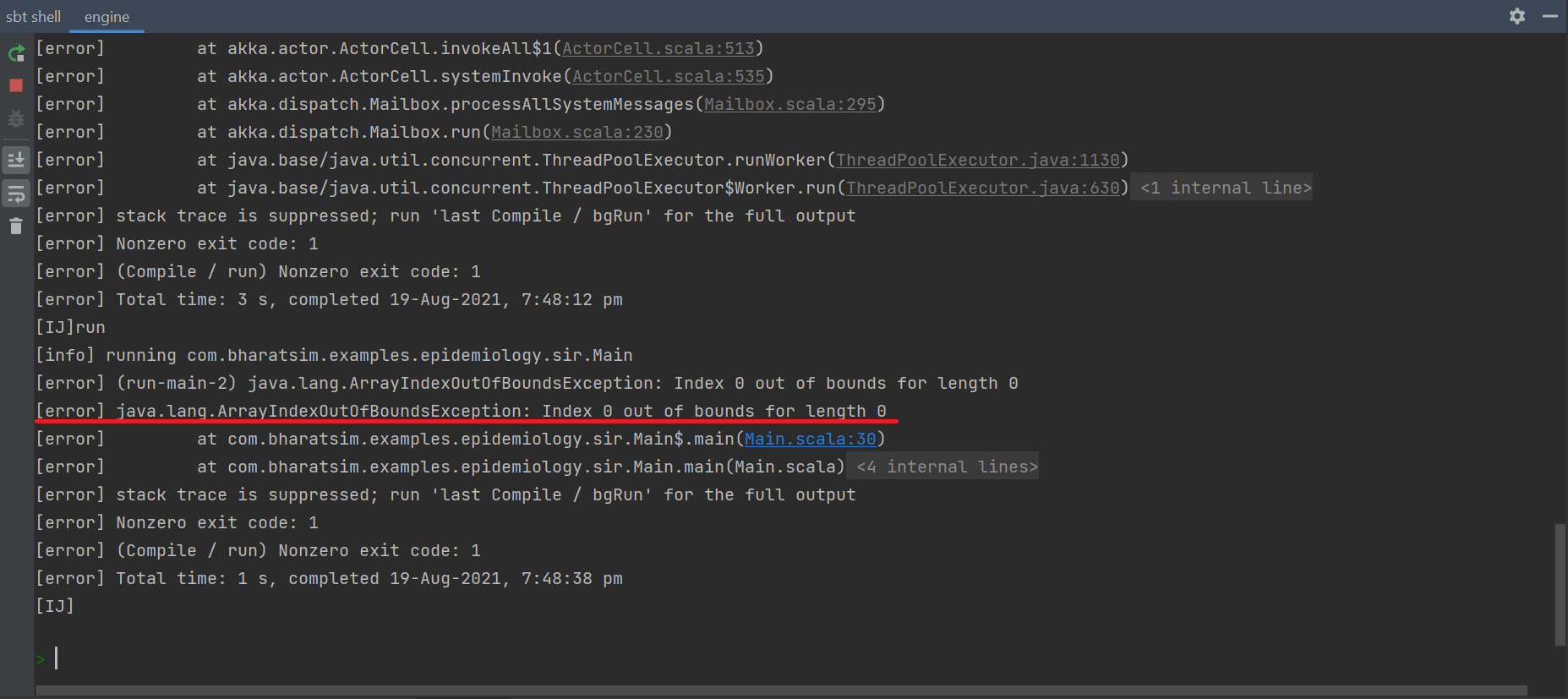
One can also run a Main file by creating a .jar file, as described above and then running java -jar file.jar [ arguments ]
Saving location-level information from the simulation
Tip
Before reading this section, it’s recommended that you read the basics in the section on Writing outputs to a CSV file.
In this section, we discuss how to create the following output:
We require the function to accept a workplace type as a string (i.e. “Home”, “Office”, “School” in our model), and create a CSV file with the output.
Each file should have the Location type (“Home”, etc.) the location ID, and the number of people per location broken up by age-group (<18, 18-45, 45-60, 60+)
Let’s call our user-defined function myCsvOutputSpec for now. First, we’ll create a scala class for it which is an extention of the CsvSpecs trait:
class myCsvOutputSpec(placeType: String, context: Context) extends CSVSpecs {}
Next, we ovverride the getHeaders function with the appropriate list of headers:
override def getHeaders: List[String] = List("PlaceType", "LocationID", "N <18", "N 18-45", "N 45-60", "N >60")
Before overriding getRows, let’s write down two functions which we’ll be needing inside of it. The first is the decodeNode method, which converts a GraphNode to a Node
def decodeNode(classType: String, node: GraphNode): Node = {
classType match {
case "House" => node.as[House]
case "Office" => node.as[Office]
case "School" => node.as[School]
}
}
The next method is called getId, and it retrieves the location ID of a GraphNode. In our program, the House, Office and School classes all have an attribute called id, so this function is designed to return that attribute.
def getId(classType: String, node: GraphNode) : Long = {
classType match {
case "House" => node.as[House].id
case "Office" => node.as[Office].id
case "School" => node.as[School].id
}
}
Caution
Looking at this function, you may think it’s unnecessary: it looks almost identical to decodeNode! Why not just use decodeNode(classType, node).id? In that case, however, note that decodeNode returns a Node, which does not have an id attribute.
By playing around with the function, you may find out that the GraphNode attribute does have an id: so why not just write the function to return node.id? The GraphNode.id attribute is a completely different number from the location ID, which is used to identify the node on the graph. As such, while the code will compile and run, the output under LocationID will have different results from what you’d expect.
Now, we can start to write down our getRows method. We want to be able to initialize a large list, every component of which is a list containing a row of the CSV file. While it sounds tempting to first initialize an empty list, and add lists to it one at a time, that is not possible in scala. This is because the List datatype is immutable - although you can define a list just fine, it cannot be changed after. We can get around this by using the ListBuffer datatype, which has a lot of useful methods.
override def getRows(): List[List[Any]] = {
val rows = ListBuffer.empty[List[String]]
}
Next we get all the nodes of the correct placeType (which, remember, was a string that the function accepts as an argument)
val locations = context.graphProvider.fetchNodes(placeType)
Iterating over each location, which we call oneLocation:
locations.foreach(oneLocation => {})
We generate a decodedLoc and locId using our decodeNode and getId functions respectively
val decodedLoc = decodeNode(placeType, oneLocation)
val locId = getId(placeType, oneLocation).toString
Note
We convert locId to a string, as it’s what we need to fill out as the second element of the row.
We then calculate the number of people in each age group who are associated with the location: This is done with getConnectionCount, where we feed in the relation between the location and the person, and then the age-requirement. We then convert the numbers to strings.
val N_0_18 = decodedLoc.getConnectionCount(decodedLoc.getRelation[Person]().get,
"age" lt 18).toString
val N_18_45 = decodedLoc.getConnectionCount(decodedLoc.getRelation[Person]().get,
("age" gte 18) and ("age" lt 45)).toString
val N_45_60 = decodedLoc.getConnectionCount(decodedLoc.getRelation[Person]().get,
("age" gte 45) and ("age" lt 60)).toString
val N_60_100 = decodedLoc.getConnectionCount(decodedLoc.getRelation[Person]().get,
"age" gte 60).toString
Now, we add this row to rows, the ListBuffer object
rows.addOne(List(placeType, locId, N_0_18, N_18_45, N_45_60, N_60_100))
Finally, outside of the iterator, we convert the ListBuffer to a List and return it
rows.toList
Putting it all together, the class is
class myCsvOutputSpec(placeType: String, context: Context) extends CSVSpecs {
override def getHeaders: List[String] = List("PlaceType", "LocationID", "N_<18", "N_18-45", "N_45-60", "N_>60")
override def getRows(): List[List[Any]] = {
val rows = ListBuffer.empty[List[String]]
val locations = context.graphProvider.fetchNodes(placeType)
locations.foreach(oneLocation => {
val decodedLoc = decodeNode(placeType, oneLocation)
val locId = getId(placeType, oneLocation).toString
val N_0_18 = decodedLoc.getConnectionCount(decodedLoc.getRelation[Person]().get, "age" lt 18).toString
val N_18_45 = decodedLoc.getConnectionCount(decodedLoc.getRelation[Person]().get, ("age" gte 18) and ("age" lt 45)).toString
val N_45_60 = decodedLoc.getConnectionCount(decodedLoc.getRelation[Person]().get, ("age" gte 45) and ("age" lt 60)).toString
val N_60_100 = decodedLoc.getConnectionCount(decodedLoc.getRelation[Person]().get, "age" gte 60).toString
rows.addOne(List(placeType, locId, N_0_18, N_18_45, N_45_60, N_60_100))
})
rows.toList
}
def decodeNode(classType: String, node: GraphNode): Node = {
classType match {
case "House" => node.as[House]
case "Office" => node.as[Office]
case "School" => node.as[School]
}
}
def getId(classType: String, node: GraphNode) : Long = {
classType match {
case "House" => node.as[House].id
case "Office" => node.as[Office].id
case "School" => node.as[School].id
}
}
}
Tip
If you want to use this code snippet, be sure to import the following
import com.bharatsim.engine.Context
import com.bharatsim.engine.basicConversions.decoders.DefaultDecoders._
import com.bharatsim.engine.basicConversions.encoders.DefaultEncoders._
import com.bharatsim.engine.graph.GraphNode
import com.bharatsim.engine.graph.patternMatcher.MatchCondition._
import com.bharatsim.engine.listeners.CSVSpecs
import com.bharatsim.engine.models.Node
import scala.collection.mutable.ListBuffer
As we only need to call this function once after data ingestion, we add the following inside simulation.defineSimulation:
var outputGenerator = new CsvOutputGenerator("output.csv", new myCsvOutputSpec("House", context))
outputGenerator.onSimulationStart(context)
outputGenerator.onStepStart(context)
outputGenerator.onSimulationEnd(context)
The output should be of the form
PlaceType |
LocationID |
N <18 |
N 18-45 |
N 45-60 |
N >60 |
|---|---|---|---|---|---|
House |
1956 |
0 |
0 |
3 |
3 |
House |
1762 |
0 |
3 |
1 |
2 |
House |
680 |
1 |
1 |
0 |
1 |
House |
1584 |
1 |
1 |
0 |
0 |
House |
1730 |
0 |
4 |
0 |
0 |
House |
2096 |
1 |
2 |
0 |
0 |
House |
1903 |
0 |
2 |
0 |
1 |
House |
1414 |
0 |
0 |
1 |
0 |
House |
1087 |
1 |
0 |
2 |
2 |
House |
652 |
1 |
0 |
0 |
2 |